

The gzip command stands for GNU Zip. It is a command-line utility that reduces the file sizes by applying the DEFLATE compression algorithm. The goal is to reduce the size of files for better storage or transmission.
File compression helps save disk space while saving bandwidth and time. As a Linux user, the gzip command makes it easy to compress files quickly, and this post will guide you in using it. Read on!
What is the gzip Command?
You might not know this, but you’ve already used the gzip compression technique when interacting with a browser. Gzip is widely used to reduce file sizes, and when accessing a web browser, the files are compressed using gzip before being sent to the client’s end.
In Linux and UNIX, gzip is one of the compression utilities you can utilize to save on disk space. The gzip command’s benefit is that it retains the original file mode and other details, such as the timestamp and ownership. Moreover, you can specify whether to keep a copy of the compressed file.
So, how do you use the gzip command? Below is its syntax.
$ gzip [options] [file]Depending on your need, you can compress a single file or multiple files. However, gzip only works with files. If you want to compress files, you must first convert them into an archive format, such as .tar, then compress them with gzip.
Note that gzip uses the .gz extension for the output.
With the gzip command, you can utilize the below options to compress your files.
| Option | Description |
| -f | Forcefully compress a file even if it is already compressed. |
| -k | Compress the file while retaining the original file. |
| -r | Compress all files in a folder recursively. |
| -v | Enable verbose mode to get information on the process. |
| -d | Decompress the file. |
| -l | Display details on the compressed file. |
The next section shows how the gzip command works by giving examples.
Practical gzip Command Examples
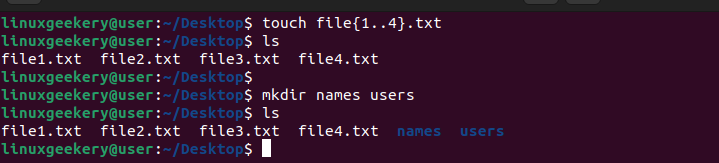
This section will focus on understanding how the gzip command works by giving examples. First, let’s use the Linux touch command to create a few files that we will use for demonstration.
$ touch file{1..4}.txt $ mkdir names usersWe’ve also run the mkdir command to create directories that will contain the created files.
With that, let’s discuss the examples.
Compressing a File
Add the target file and any option you wish to include to compress a file using gzip. For this example, we are compressing a single file with the below command.
$ gzip file1.txtWhen we run the ls command, we confirm that we now have a .gz version of the original file, which got deleted after the compression.

That’s the primary way to compress a file in Unix or Linux.
Compress a File and Retain the Original File
In the previous example, we saw that the original file was deleted after the gzip compression. However, you can add the -k option to keep the original file.
$ gzip -vk file2.txtWe’ve also included the -v option to see information on what is happening. Notice how, in this case, our ls command returns the created .gz file, and our original file also exists.

Compressing Multiple Files
Sometimes, you may have a case where you want to compress numerous files. Luckily, the gzip accepts multiple files; you only need to specify their names, as in the command below.
$ gzip -v file3.txt file4.txtYou will get an output showing all the compressed versions of the original file.

Forcefully Compress a File
When you try compressing a file whose compressed version already exists, you will get prompted to confirm overwriting it.
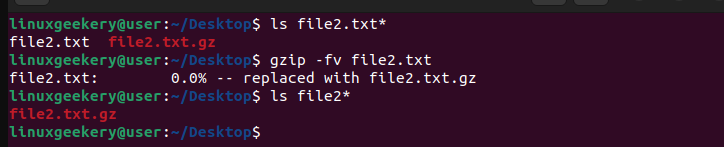
Here’s an example where we have the file2.txt and its compressed version, file2.txt.gz.
$ gzip file2.txt
In the prompt, you can confirm to overwrite the existing compressed version or stop the compression. Alternatively, you can forcefully overwrite any existing compressed target file version by adding the -f option.
$ gzip -fv file2.txtSince we’ve not included the -k option, we don’t have the original file after the compression occurs.
How to Decompress a File with the gzip Command
Suppose you’ve compressed a file and wish to revert to its original format. Worry not; the -d option will decompress the file. Taking the ‘file1.txt.gz’ as our example, we can decompress it as follows.
$ gzip -dv file1.txt.gzWe now get the original ‘file1.txt’ file.

View Contents of a Compressed File
After creating a .gz file using the gzip command, it’s possible to open the file to display its contents. However, instead of using gzip, we will use the zcat command.
First, let’s append our ‘file1.txt’ using the cat command.
$ cat >> file1.txt
Next, compress the file using gzip. To view the contents of the compressed file, run the zcat command and specify the compressed file that you want to display its contents.
$ gzip -v file1.txt
$ zcat file1.txt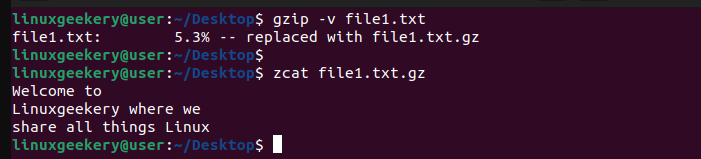
gzip Recursively Compress Directory Contents
Suppose you have a directory containing files and want to compress them. Since you can’t compress the directory using gzip, the best approach is to recursively compress all the included files by adding the -r option.
First, run the Linux mv command to move files to the target directory.
$ mv -v *.gz names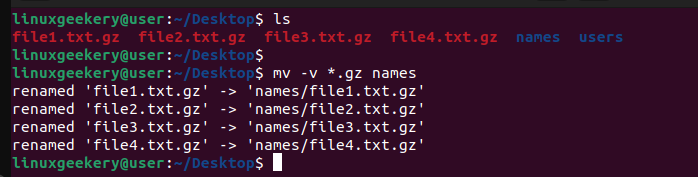
Our file contains .gz, text, and .sh files. To compress all the files, we will run the below command.
$ gzip -rv names/The output will show how the compression occurs. The compressed files will remain unchanged, but the .txt and .sh files will be compressed.
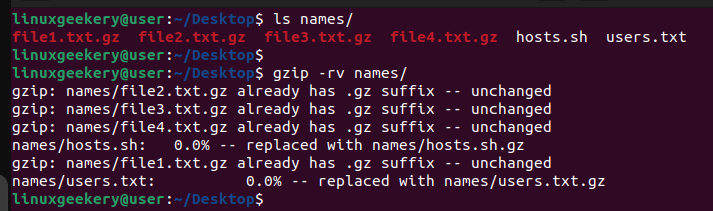
Similarly, if you have different sub-folders containing files, you can use the -r option to compress the included files.
Let’s use the tree command to see the hierarchical structure of our target directory.
$ tree Students/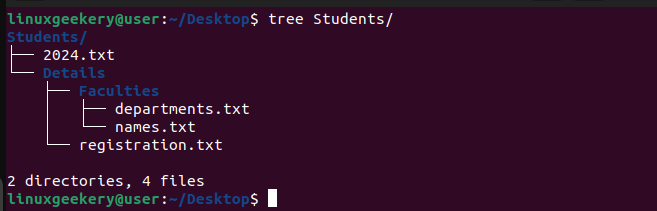
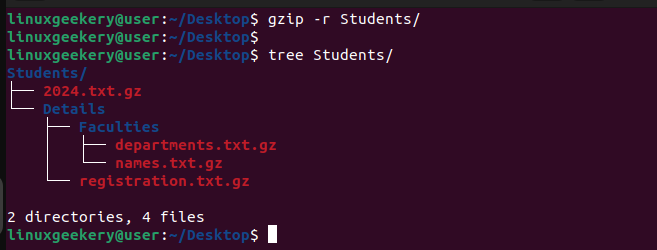
Using the command below, we can compress all the files at the different sub-directory levels.
$ gzip -r Students/Rerunning the tree command, we see that all our files are now compressed, regardless of the level down the hierarchy.
How to Decompress Recursively
We’ve seen how you can recursively compress all files in a directory. To decompress the files, use the -d option, which is similar to what we did with files. However, you must add the -r since the files are inside a directory.
Here’s an example.
$ gzip -rdv names/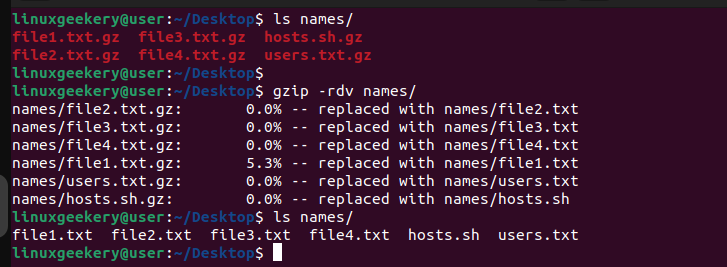
View Information on the Compressed File
We’ve already seen how you can view the contents of a compressed file using the zcat command. However, if you want to get information regarding the compressed file, such as the compression ratio and the compressed file size expressed in bytes, add the -l option.
First, run your command as follows if dealing with files inside a directory.
$ gzip -rl names/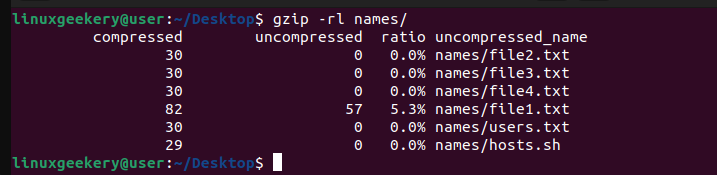
If dealing with a compressed file, remove the -r option.
$ gzip -l names/file1.txt.gz
gzip Command Compress tar Files
There are different reasons why compressing tar files is essential. For instance, if you want to compress a directory, you must archive it and then compress it.
For this example, we’ve created a tar file containing files.
$ tar cvf tar_files.tar names.sh update.sh list.txt
We can then compress the tar file.
$ gzip -v tar_files.tarThe original tar file will be deleted, and the .gz file will replace it.

Note: gzip mainly compresses text files and tar archives. Therefore, don’t try using it with symbolic links or other files such as images, PDF, video, or audio.
Conclusion
The gzip command helps compress files to reduce their size. Doing so saves on space, time, and bandwidth. The command takes different options, and the examples covered in this post demonstrate different options you can use to compress your files. Have fun compressing your files!



